A microservice architecture encourages granularity which results in the invocation of significantly more services via network connections than more monolithic architectures. This makes optimising the network latency for each microservice key to delivering responsive business services.
Service time is the time taken for a client to invoke a service and receive a response. It is the sum of network latency and the internal service time of the invoked service. Internal service time is the time taken for a service provider to generate a response ready for transmission, which is constrained by the finite availability of CPU, memory and I/O resource.
Network latency consists of the time taken to serialize and deserialize a message before and after transmission, which is a function of message size, and the distance the serialized message must travel - signals are transmitted at ~2/3rds the speed of light over fibre optic and coaxial copper cables.
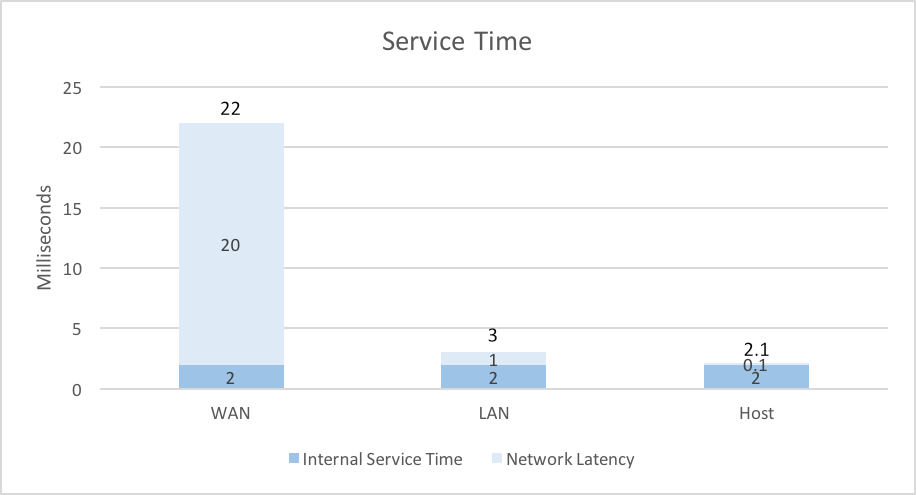
Network latency can dominate the service time of a microservice. This is illustrated in the chart below, which shows the service times for a trivial microservice with an internal service time of 2 milliseconds when invoked via wide area network connected to an external provider in the same city, a local area network and a host network.
When a microservice is composed of several microservices, the network latencies accumulated as part of the service time for each invoked microservice can be significant. The chart below shows the network latencies and internal service times of a stereotypical Order microservice composed of Customer and Warehouse microservices hosted on the same machine and a Payment service served via an external provider in the same city, a microservice in the local area network and a microservice hosted on the same machine.
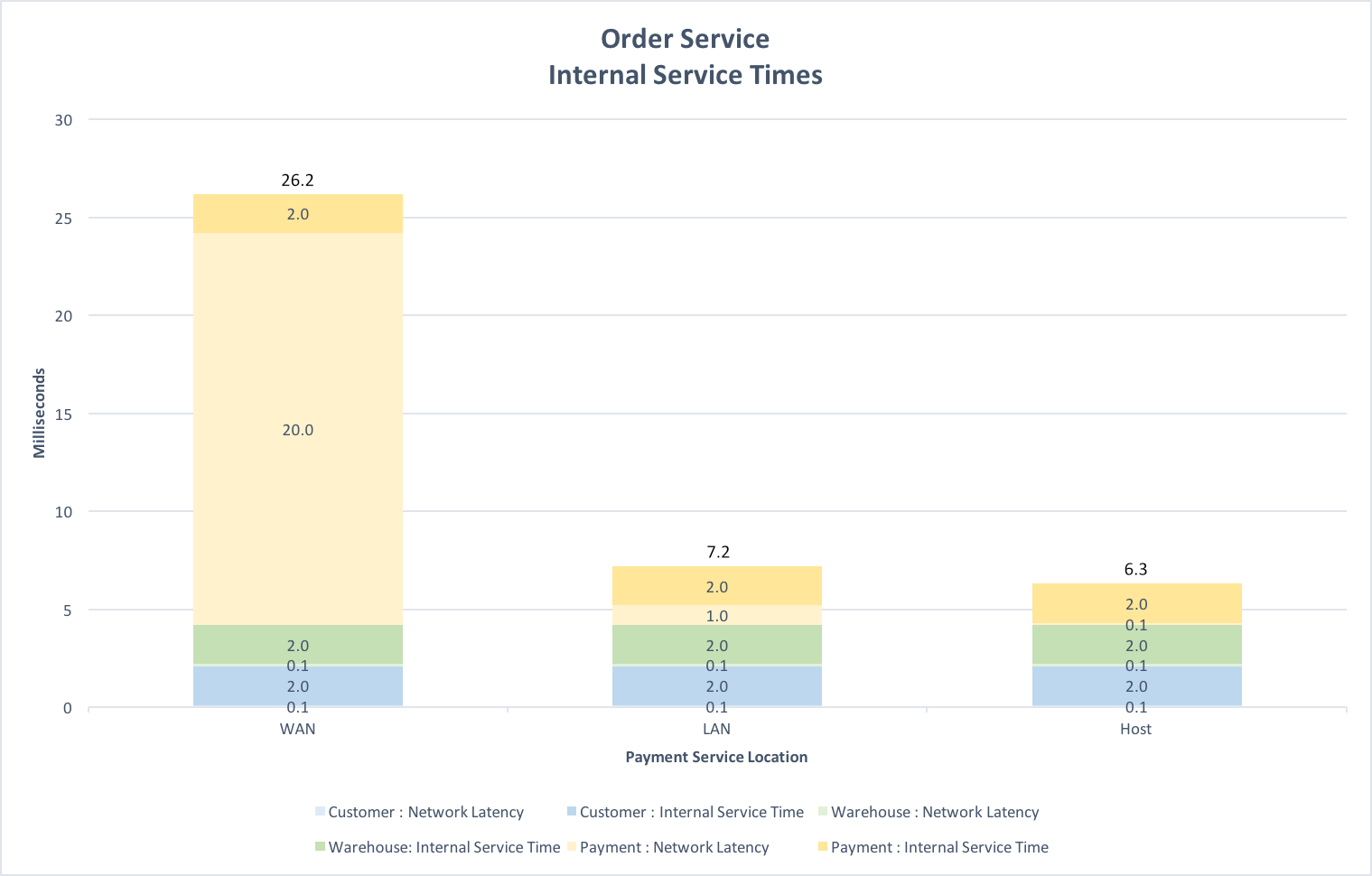
Clearly the network latency incurred when the Payment service is invoked over a wide area network dominates the internal service time of the Order service. One solution is for the external Payment service provider to support a gateway deployed on the customers’ internal network that authorises low risk payments without recourse to the external service. As shown above, both LAN and Host deployments vastly reduce the service time of the Order service.
The Payment service gateway must still send payment details to the external provider, but for those payments authorised locally, this is done asynchronously so as not to impact the service time of the Order service.
This is a common scenario for messages sent outside of the primary request/response path. Here the service time for individual messages is less critical allowing overall message throughput to be optimised. One approach is to use a batch strategy.
Batch Strategy
A batch strategy ameliorates the cost of network latency over multiple messages by sending many in a single envelope message. Messages are collected in a time and size bounded envelope which is sent as a single message when either bound is exceeded. For an unconstrained system, the mean service time for each message sent in the envelope when triggered by the time bound is (network latency / envelope message size) + (time bound / 2) + internal service time. With the same condition, when triggered by the size bound the mean service time is (network latency / envelope message size) + (collection time / 2) + internal service time.
Apache Kafka natively implements a batch strategy. It can be implemented using messaging transports that do not do so natively, such as gRPC.
The snippet below shows the service and messages definitions used to implement a batch strategy in Protocol Buffer 3 syntax, the default encoding for gRPC:
syntax = "proto3";
import "google/protobuf/any.proto";
service Envelope {
rpc Post (EnvelopeRequest) returns (EnvelopeResponse) {}
}
message EnvelopeRequest {
repeated Request requests = 1;
}
message EnvelopeResponse {
repeated Response responses = 1;
}
message Request {
UUID correlationId = 1;
Method method = 2;
google.protobuf.Any message = 3;
}
message Response {
UUID correlationId = 1;
google.protobuf.Any message = 2;
}
message UUID {
uint64 least_sig_bits = 1;
uint64 most_sig_bits = 2;
}
message Method {
string name = 1;
}
Using extension points provided by gRPC the batch strategy is implemented by intercepting selected client RPC invocations and collecting them in a time and size bounded queue. The contents of the queue are sent to the server in an EnvelopeRequest message when either of the queue bounds is exceeded. The server unpacks the EnvelopeRequest and for each Request invokes the intercepted service. The service side responses are collected and when all are received returns them to the client as an EnvelopeResponse message. The client interceptor unpacks the EnvelopeResponse and for each Response completes the intercepted invocation by returning the message.
This lightweight implementation is only resilient to the extent that the client will receive a timeout error should the RPC invocation fail to return a response after a configured period. When the services invoked are idempotent this is usually sufficient.
Idempotence
When invoked services are idempotent this is often the only resilience that a client requires. Providing the client sends precisely the same data it is free to retry as many times as necessary until it receives a response. This is particularly useful when the client orchestrates several idempotent services as it can restart the orchestration from any point. For example, the above mentioned stereotypical Order service can restart the orchestration of Customer, Warehouse and Payment services from the beginning providing they are idempotent and precisely the same data is posted with a unique transaction identifier.
Passing Thoughts
A focus of this musing has been on the influence of network latency on service time. The figures used are examples which will vary according to the performance and configuration of the network fabric.
There are scenarios when the network can be bypassed entirely. Container environments such as Apache Mesos, Docker and Kubernetes support the sharing of volumes between containers on the same host. This allows the transmission of messages between the microservices deployed in these containers without interacting with the network.
Such an approach is worthwhile when the installed network fabric does not implement a solution that avoids unnecessary network layers when routing traffic between cohosted containers.
There is still latency. As with network I/O, when a volume is used messages must be serialized prior to writing and deserialized after reading. However, the time taken to write and read from a volume is generally much faster than that over a network, especially for volumes that perform in memory data transfer.
Protocol Buffers can be used for serializing and deserializing message via volumes, which is particularly useful if gRPC is used for network messaging as the same message definitions generated by the IDL tooling can be used for both. Similarly, when using REST with RAML IDL or Apache Avro with the Avro IDL.